(Fast) spamfrei browsen mit squid & privoxy
- /etc/squid3/squid.conf
- /etc/squid3/allowed_users
- /etc/privoxy/config
- /etc/privoxy/user
- Die Nachteile
Das Jahr neigt sich dem Ende zu, und ich habe Zeit und Lust, eine etwas umfangreichere Pfriemelei vorzustellen: Browsen über die Caches squid und privoxy.
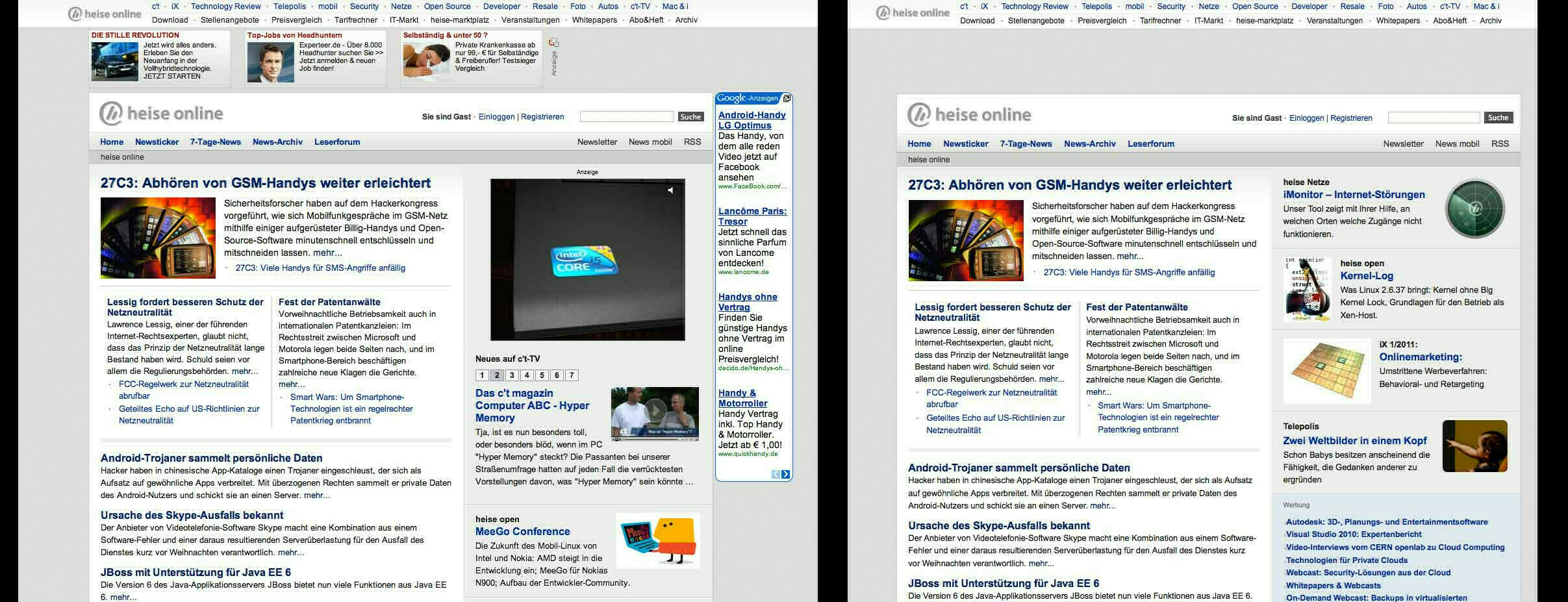
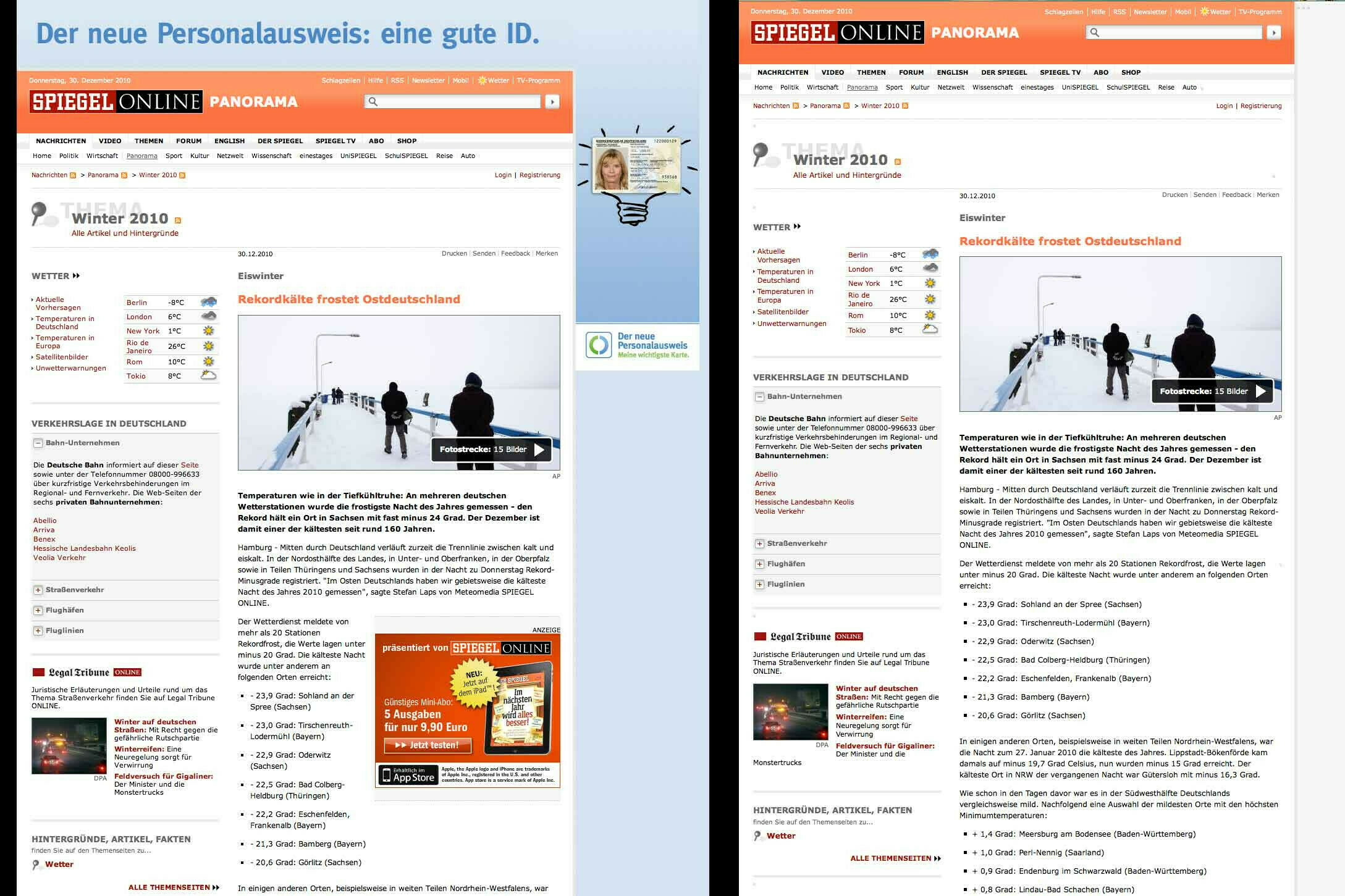
Damit verfolge ich zwei Ziele: zum einen möchte ich einen caching proxy einsetzen, der häufig angeforderte Inhalte wie kleine Bildchen beispielsweise direkt ausliefert, ohne sie wieder und wieder vom entfernten Server abrufen zu müssen; zum anderen möchte ich einen filtering proxy, der mir unerwünschte Inhalte abblockt. Unerwünschte Inhalte können zum einen Werbeanzeigen, hüpfende Banner, diese nervigen Flash-Einblendungen usw. sein, möglicherweise aber auch alles, was eine ohnehin langsame Leitung ausbremst, das Surf-Verhalten protokolliert – je nach Einsatzzweck halt. Zusätzlich besteht die Möglichkeit, die wahre Identität ein wenig zu verschleiern, indem man sich beispielsweise als den standardkonformsten Browser der Welt ausgibt. Beachtet zur Illustration die beiden Bilder: einmal heise.de, einmal spiegel.de, links normal aufgerufen – also ohne Proxy – und rechts im Bild die Ausgabe, die ich beim Surfen über die Proxies erhalte.
Wenn ich ehrlich bin: ich bin immer wieder überrascht, wie nervig das Internet doch ist, muss man es denn ungefiltert verwenden. Und das ist auch der Grund, weshalb ich mich für die serverbasierte Lösung entschieden habe: das No-Script-Plugin für Firefox macht einen ähnlichen Job, aber es hat aus meiner Sicht zwei Nachteile:
- Es ist ein Firefox-Plugin – andere Browser haben nichts davon.
- Es muss konkret auf einem Rechner installiert und das Regelwerk erweitert werden; ich nutze über die Woche aber drei verschiedene Rechner regelmäßig.
Zur Erklärung versuche ich nachfolgend aufzuzeigen, wie der Abruf der Webseite heise.de bei mir funktioniert:
- Der Browser ist derart konfiguriert, dass er einen Proxy verwendet (Adresse des Servers, Port 3128).
- Ich rufe
heise.dein diesem Browser auf. - Der verbindet sich auf Port 3128 auf den Server (squid caching proxy).
-
squidgibt die Anfrage weiter an Port 8118 (privoxy filtering proxy) filtert sie seinen Regeln entsprechend. -
squidspeichert Daten im Cache, seiner Konfiguration entsprechend, bzw. liefert aus seinem Cache, was er schon drin hat.
Die Installation von squid und privoxy erfolgt auf einem Ubuntu-System ganz regulär über apt-get install; ich gehe an dieser Stelle lediglich auf die Konfigurationsdetails ein.
/etc/squid3/squid.conf
cache_peer 127.0.0.1 parent 8118 7 no-query
http_port 3128
cache_mgr meine@mailadres.se
cache_effective_user proxy
cache_effective_group proxy
error_directory /usr/share/squid3/errors/de
auth_param basic program /usr/lib/squid3/pam_auth
auth_param basic children 5
auth_param basic realm Squid proxy-caching web server
auth_param basic credentialsttl 2 hours
acl manager proto cache_object
acl localhost src 127.0.0.1/255.255.255.255
acl to_localhost dst 127.0.0.0/8
acl SSL_ports port 443 563
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 563 # https, snews
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
acl CONNECT method CONNECT
acl allowed-users proxy_auth "/etc/squid3/allowed_users"
acl x-type req_mime_type -i ^application/vnd.google.safebrowsing-chunk$
acl x-type req_mime_type -i application/vnd.google.safebrowsing-chunk
http_access deny x-type
request_header_access From deny all
request_header_access Referer deny all
request_header_access Server deny all
request_header_access X-Forwarded-For deny all
request_header_access Via deny all
request_header_access User-Agent deny all
request_header_access WWW-Authenticate deny all
request_header_access Link deny all
http_access allow localhost
http_access allow allowed-users
http_access deny all
request_header_access User-Agent deny all
header_replace User-Agent Gozilla/4711.0815 (CP/M; 11-bit; 42 KByte)
cache_access_log /var/log/squid3/access.log
cache_log /var/log/squid3/cache.log
cache_store_log /var/log/squid3/store.log
/etc/squid3/allowed_users
In der Datei steht schlicht eine Liste von Usern, die das System nutzen dürfen; geregelt wird der Zugriff dann über /etc/pam.d/squid. Kann selbstredend auch weggelassen werden, doch dann sollte der Zugang zum Proxy auf andere Arten reglementiert werden (VPN-Netz o.ä.). Man möchte ja nicht den Traffic anderer Leute über den eigenen Server schleusen, oder?
/etc/privoxy/config
user-manual /usr/share/doc/privoxy/user-manual
confdir /etc/privoxy
logdir /var/log/privoxy
actionsfile standard
actionsfile global
actionsfile default
actionsfile user
filterfile default.filter
logfile logfile
debug 1
debug 128
debug 4096
debug 8192
listen-address 127.0.0.1:8118
toggle 1
enable-remote-toggle 1
enable-remote-http-toggle 1
enable-edit-actions 1
buffer-limit 4096
forwarded-connect-retries 0
/etc/privoxy/user
Das ist der eigentlich umständliche Teil der Sache: hier geht es darum, das Regelwerk um eigene Regeln zu erweitern. Meine Vorgehensweise hierzu:
- Das Regelwerk des No-Script-Plugins exportieren und entsprechend aufbereiten.
- Diese Regeln schonmal in die Konfiguration aufnehmen.
- Dann das Debug-Fenster von No-Script aktivieren; hier sieht man sehr deutlich, was pro Seite geblockt wird – und vor allem, was nicht!
- Anhand dessen lässt sich das Regelwerk nun sehr fein anpassen. Bei mir sieht das beispielsweise so aus:
{+block{Various domains as known adservers} +handle-as-image}
.adcell.de
.adform.net
Ich habe die Einträge alphabetisch durchsortiert, um nicht den Überblick zu verlieren; ihr versteht bitte, dass ich euch das vollständige Regelwerk nicht zur Verfügung stellen kann, aber sich ein eigenes Regelwerk zusammenzustellen ist reine Fleißarbeit – und glaubt mir, es lohnt sich. So sind es oftmals die diversen Analytics-Server, die sehr lange Antwortzeiten haben und die den Seitenaufbau massiv ausbremsen – auf diese Art hat man die theoretische Möglichkeit, das zu umgehen.
Die Nachteile
Auch die Nachteile einer solchen Lösung sollen nicht verschwiegen werden. So verschleiert man natürlich überhaupt nichts, wenn man sich als User-Agent Gozilla/4711.0815 (CP/M; 11-bit; 42 KByte) ausgibt – im Gegenteil, das macht es nur leichter, ein Bewegungsprofil zu erstellen. Will man den Header also ersetzen, dann sollte man sich für einen 08/15-String entscheiden. Weiter gibt es Seiten, bei denen es erwünscht ist, massenhaft kleine Bildchen zu sehen – so beispielsweise fotocommunity.de, bei der die Thumbnails auf den Übersichtsseiten weggeblockt wurden; Abhilfe schafft hier eine Ausnahmeregel. Ausnahmeregeln habe ich in den ersten vier Betriebswochen definiert und hernach nie wieder anrühren müssen.
{ -filter{banners-by-size} }
.fotocommunity.de
Arbeitet man an einem !Windows-Rechner und möchte sich eine Software herunterladen, so kann es für Verwirrung sorgen, wenn man den Header-String durch einen Windows-Client ersetzt – manche Webseiten beginnen anhand des Header-Strings automatisch mit dem Download von Software, was dann dazu führt, dass einem ständig .exe-Dateien präsentiert werden ;) Hier muss man im Hinterkopf behalten: Proxy. Proxy. Proxy.

Manche Webseiten sind auch einfach zu klug: Vimeo beispielsweise hat mich nach den ersten drei Requests einfach geblockt. Allerdings habe ich immer zwei Browser installiert, und in meinem Fall ist es der Safari, der nicht auf die Verwendung der Proxies konfiguriert ist; sollte ich eine Seite also wirklich nicht betrachten können, kann ich sie theoretisch immer im Ausweich-Browser öffnen – wenn ich das wirklich will. Will ich aber eigentlich nie – hat immer einen Grund, weshalb sie nicht angezeigt wird (manchmal genügt ein Blick auf die Adresse).
Zur Verdeutlichung: zur Anonymisierung ist das Setup in dieser Form nicht gedacht; denn die Requests kommen ja dann fortwährend von der Server-IP (die in der Regel statisch ist) und nicht mehr von eurem DSL-Anschluss (dessen IP sich ja zumindest theoretisch regelmäßig ändert). So, nun viel Spaß beim Selberbasteln. Und berichtet mal, ob’s funktioniert hat!
Hintergrundbild: 2414x 927px, Bild genauer anschauen – © Marianne Spiller – Alle Rechte vorbehalten