MySQL NDB Cluster: Geographic Master-to-Master-Replication
Weitere Beiträge der Artikelserie „MySQL NDB Cluster“ findest du an dieser Stelle.
Es ist mit Sicherheit die aufwendigste experimentelle Setup, das ich bisher aufgezogen habe, es sind ziemlich viele virtuelle Maschinen involviert:
- vier Data&SQL Nodes, die den
mysqldsowie denndbdzur Verfügung stellen sowie - vier Management Nodes, die neben dem
ndb_mgmdauch denmysql-proxyzur Verfügung stellen; darüber hinaus - eine weitere VM webserver zum Testen, in der WordPress & Co. testweise aufziehe.
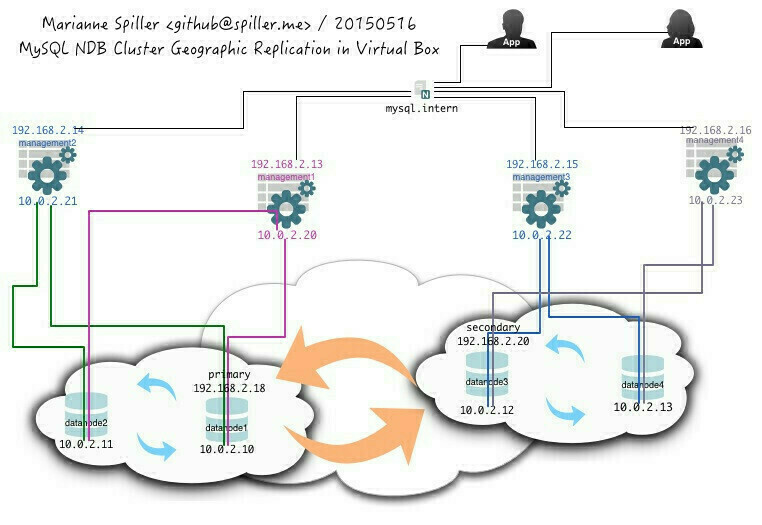
Meine Ausgangsbasis ist mein MySQL NDB Cluster GREEN, das ich auf dem Mac Pro in VirtualBox aufgezogen habe wie hier beschrieben. Dieses Setup habe ich (der Übersichtlichkeit halber mit anderen IP-Adressen) auf dem iMac wiederholt und so Cluster BLUE erstellt. Zur Veranschaulichung habe ich mal versucht, auch dieses Setup graphisch darzustellen – gar nicht so einfach :D Die Replikation innerhalb der beiden Cluster (also datanode1 + datanode2 in GREEN bzw. datanode3 + datanode4 in BLUE) ist, wir erinnern uns, synchron, wohingegen die Replikation über die Rechenzentrumsgrenze hinweg (in meinem Falle also von einem Stockwerk ins andere) asynchron sein wird. Der Wert seconds behind master ist etwas, das auf jedem Slave unbedingt überwacht werden muss – beispielweise per Nagios/ Icinga.
In meinem Setup wird datanode1 (primary) sowohl Master als auch Slave für datanode3 (secondary) sein – und umgekehrt. Darum muss ich beide Data Nodes um ein Netzwerk-Interface (bridged) erweitern, so dass sie miteinander kommunizieren können – anhand ihrer MAC-Adressen vergebe ich auch hier feste IPs und auch Hostnamen. Es wäre natürlich auch hier möglich, alle vier Data Nodes heranzuziehen, sie über Kreuz zu replizieren,… Nunja, es ist ein experimentelles Setup. Schon vor einigen Jahren habe ich mich mit der Replikation beschäftigt, und im Grunde genommen ist es hier nicht anders – es hängt halt ein ganzer Verbund von Hosts dran und nicht nur zwei.
Auf datanode1, dem Primary, lege ich mir zwei Replikations-User an, die ich benötigen werde:
## file: "/root/.bash_profile"
alias Connect1="mysql -u root -pPasswort --prompt 'primary> '"
primary> CREATE USER 'replication'@'192.168.2.20'
-> IDENTIFIED BY 'unsicher';
Query OK, 0 rows affected (0.20 sec)
primary> CREATE USER 'replication'@'192.168.2.18'
-> IDENTIFIED BY 'unsicher';
Query OK, 0 rows affected (0.22 sec)
primary> GRANT REPLICATION SLAVE ON *.* to 'replication'@'192.168.2.20';
Query OK, 0 rows affected (0.06 sec)
primary> GRANT REPLICATION SLAVE ON *.* to 'replication'@'192.168.2.18';
Query OK, 0 rows affected (0.04 sec)
Dann müssen die Datenbanken von datanode1 auf datanode3 transportiert werden: in Form von MySQL-Dumps, oder indem ihr datadir per rsync oder so übertragt – es sei euch überlassen. Beachtet halt die Einschränkungen, die jede Vorgehensweise so hat. Sobald ihr auf dem Secondary den Datenbestand bekannt gemacht habt, kennt auch dieser Host unsere replication-User – hier besteht nun also kein Handlungsbedarf mehr.
Nun geben wir dem MySQL-Server auf dem Secondary eine erweiterte my.cnf – ich habe an dieser Stelle auch dafür gesorgt, dass meine Datenbanken unter /var/lib/mysql-cluster/data abgelegt werden und nicht mehr in /usr/local/mysql/data, aber das ist Geschmackssache – wenn ihr es nicht benötigt, kommentiert es einfach aus, und falls doch, dann achtet darauf, dass das Verzeichnis existiert und dem User mysql gehört. (Re)startet /etc/init.d/mysql.server und loggt euch ein – weil ich faul bin, hab ich mir inzwischen einen alias in die .bash_profile gesetzt:
## file: "/root/.bash_profile"
alias Connect2="mysql -u root -pPasswort --prompt 'secondary> '"
Verklickern wir dem Secondary, dass der Primary sein Master-Server ist, dass er sich mit diesem verbinden soll – und zwar über den vorhin angelegten User replication:
secondary> CHANGE MASTER TO MASTER_HOST='192.168.2.18',
-> MASTER_USER='replication',
-> MASTER_PASSWORD='unsicher',
-> MASTER_LOG_FILE='',
-> MASTER_LOG_POS=4;
Query OK, 0 rows affected, 2 warnings (0.06 sec)
secondary> START SLAVE;
Query OK, 0 rows affected (0.04 sec)
Der Secondary ist bereit; nun muss der Primary noch an den Start gebracht werden. Hierzu geben wir auch ihm eine erweiterte my.cnf und starten den Dienst durch. Hernach loggt sich der root-User ein und vermittelt dem Primary, dass der Secondary sein Master sein soll:
primary> CHANGE MASTER TO MASTER_HOST='192.168.2.20',
-> MASTER_USER='replication',
-> MASTER_PASSWORD='unsicher',
-> MASTER_LOG_FILE='',
-> MASTER_LOG_POS=4;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
primary> START SLAVE;
Query OK, 0 rows affected (0.00 sec)
Prüfen wir nun auf beiden Knoten, ob sie auch wirklich als Master agieren:
secondary> show master status;
+-----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------------+----------+--------------+------------------+-------------------+
| blue-bin.000013 | 120 | | | |
+-----------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
primary> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| green-bin.000010 | 120 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
Mittels show slave status\G können wir auf den Knoten prüfen, ob sie artige Slaves sind; läuft alles, wird in den Fehlermeldungen nichts angezeigt und der Status besagt, dass der Slave auf Daten vom Master wartet:
[...]
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
[...]
Seconds_Behind_Master: 0
[...]
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
[...]
Lassen wir uns doch mal anzeigen, was sich auf den Kisten gerade tut, zuerst auf dem Primary und dann auf dem Secondary:
primary> show processlist;
+----+-------------+----------------------------+------+-------------+------+-----------------------------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------------+----------------------------+------+-------------+------+-----------------------------------------------------------------------------+------------------+
| 1 | system user | | | Daemon | 0 | Waiting for event from ndbcluster | NULL |
| 2 | system user | | NULL | Connect | 5328 | Waiting for master to send event | NULL |
| 4 | replication | blue-master.bafi.lan:43641 | NULL | Binlog Dump | 5313 | Master has sent all binlog to slave; waiting for binlog to be updated | NULL |
| 37 | root | localhost | NULL | Query | 0 | init | show processlist |
| 40 | system user | | NULL | Connect | 279 | Slave has read all relay log; waiting for the slave I/O thread to update it | NULL |
+----+-------------+----------------------------+------+-------------+------+-----------------------------------------------------------------------------+------------------+
5 rows in set (0.01 sec)
secondary> show processlist;
+------+-------------+-----------------------------+------+-------------+--------+-----------------------------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+------+-------------+-----------------------------+------+-------------+--------+-----------------------------------------------------------------------------+------------------+
| 1 | system user | | | Daemon | 0 | Waiting for event from ndbcluster | NULL |
| 2 | system user | | NULL | Connect | 172178 | Waiting for master to send event | NULL |
| 1124 | replication | green-master.bafi.lan:44263 | NULL | Binlog Dump | 5244 | Master has sent all binlog to slave; waiting for binlog to be updated | NULL |
| 1139 | root | localhost | NULL | Query | 0 | init | show processlist |
| 1161 | system user | | NULL | Connect | 191 | Slave has read all relay log; waiting for the slave I/O thread to update it | NULL |
+------+-------------+-----------------------------+------+-------------+--------+-----------------------------------------------------------------------------+------------------+
5 rows in set (0.00 sec)
Fügen wir nun einen Datensatz – beispielsweise den neuen User owntracks – auf datanode1 hinzu, so wird dieser synchron (NDB) an datanode2 übermittelt (aufgrund dessen, dass wir Distributed Privileges eingerichtet haben), asynchron an datanode3 (Replikation) und von dort wiederum synchron an datanode4 (NDB). Und sind wir schnell genug, können wir per show processlist sehen, wie der neue User auf dem Slave ankommt:
secondary> show processlist;
+----+-------------+-----------+------+---------+------+-----------------------------------+------------------------------------------------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------------+-----------+------+---------+------+-----------------------------------+------------------------------------------------------------------------------------------------------+
| 1 | system user | | | Daemon | 0 | Waiting for event from ndbcluster | NULL |
| 2 | root | localhost | NULL | Query | 0 | init | show processlist |
| 3 | system user | | NULL | Connect | 591 | Waiting for master to send event | NULL |
| 4 | system user | | | Connect | 112 | System lock | CREATE USER 'owntracks'@'10.0.2.%' IDENTIFIED BY PASSWORD '*46011C99C810D2421F952615C13C8E0E4CF039A' |
+----+-------------+-----------+------+---------+------+-----------------------------------+------------------------------------------------------------------------------------------------------+
4 rows in set (0.00 sec)
secondary> show processlist;
+----+-------------+-----------+------+---------+------+-----------------------------------+---------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------------+-----------+------+---------+------+-----------------------------------+---------------------------------------------------------------+
| 1 | system user | | | Daemon | 0 | Waiting for event from ndbcluster | NULL |
| 2 | root | localhost | NULL | Query | 0 | init | show processlist |
| 3 | system user | | NULL | Connect | 610 | Waiting for master to send event | NULL |
| 4 | system user | | | Connect | 107 | System lock | grant all privileges on owntracks.* to 'owntracks'@'10.0.2.%' |
+----+-------------+-----------+------+---------+------+-----------------------------------+---------------------------------------------------------------+
4 rows in set (0.00 sec)
Testweise habe ich dann die Datenbank meines Blogs eingefüttert – und dumm geguckt dabei. Denn: verbinde ich mich mit mysql.intern, so habe ich die 50%ige Wahrscheinlichkeit, auf datanode2 zu landen. Dieser nimmt die Daten zwar an, verteilt sie aber nicht an datanode1 – da die Engine auf InnoDB steht. Das ist der Grund, weshalb Cluster der Secondary die Daten überhaupt nicht erhält! Erst mit einem ALTER TABLE zu ENGINE=NDBCLUSTER wird für die Verteilung der Daten gesorgt. Installiere ich hingegen ein neues WordPress (oder was auch immer), so sorgt der Eintrag default-storage-engine=NDBCLUSTER in der my.cnf dafür, dass die Engine der Tabellen direkt richtig gesetzt wird.
In meinem experimentellen Setup kann ich jetzt meinen DNS-Eintrag mysql.intern um die IPs von management3 und management4 erweitern und auf beiden jeweils, analog zu Cluster GREEN, einen mysql-proxy aufsetzen; stattdessen könnte mysql.intern auch wiederum ein Loadbalancer sein, der erst die Verfügbarkeit prüft und dann Verbindung aufbaut. Oder. Oder. Oder… :D
Hier ist dann bedauerlicherweise der Punkt erreicht, an dem mein experimentelles Setup aussteigt; zum einen liegt das daran, dass der iMac nur 16GB RAM hat, wovon in der jetzigen Konstellation 14GB belegt sind. Der zweite Schwachpunkt ist das Netzwerk: während der Mac Pro im Untergeschoss sehr stabil am Netzwerk hängt, ist der obere iMac über ein wüstes WLAN-Repeater-Setup am Netz. Überdurchschnittlich oft habe ich daher das Problem, dass sich auf halbem Wege etwas weghängt und die Replikation – zumindest in eine Richtung – stoppt.
The incident LOST_EVENTS occured on the master. Message: cluster disconnect.
Das lässt sich auf dem Slave durch ein (notfalls mehrmaliges) SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; beheben:
primary> SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1;
Query OK, 0 rows affected (0.00 sec)
primary> start slave;
Query OK, 0 rows affected (0.00 sec)
primary> show slave status\G
An diesem Punkt beende ich meine experimentelle Geo-Replikation leider schon wieder, aber ich weiß nun, wie sie prinzipiell funktioniert – und das ist ja auch schon viel wert. Und mit diesem wüsten Artikel verabschiede ich mich ins Wochenende – und wünsche euch eine tolle Zeit :-)
Hintergrundbild: 762x 525px, Bild genauer anschauen – © Marianne Spiller – Alle Rechte vorbehalten
{kind=link}