MySQL NDB Cluster: mehrere ndbd-Instanzen auf einem Host
Weitere Beiträge der Artikelserie „MySQL NDB Cluster“ findest du an dieser Stelle.
Unser MySQL NDB Cluster besteht aus mehreren Servern: aus zwei Management Nodes und aus zwei Data Nodes. In unserem Setup stellen die Data Nodes sowohl jeweils einen mysqld zur Verfügung als auch den ndbd – es kann aber sinnvoll sein, auch für jede Aufgabe eigene Hosts zur Verfügung zu stellen. mysqld ist mysqld, wie man ihn kennt – er lauscht auf Port 3306, er wird über die my.cnf konfiguriert, hat ein Socket, ein Logfile und so weiter. Das Besondere am Cluster sind die ndbd-Instanzen, die Datenknoten, auf denen jene Tabellen abgelegt werden, die ENGINE=NDBCLUSTER verwenden: mit NoOfReplicas=2 haben wir definiert, dass sie paarweise repliziert werden – jeweils zwei ndbd-Instanzen bilden eine Node Group – und alle Schreiboperationen werden auf allen Datenknoten immer synchron durchgeführt. Das heißt: zu jedem Zeitpunkt ist der Datenbestand auf jedem Datenknoten identisch.
Es ist möglich, auf einem Host mehrere Instanzen des ndbd laufen zu lassen – pro Core eine. Da diese Instanzen sich paarweise replizieren sollte man peinlich darauf achten, dass sie sinnvoll auf die Hosts verteilt werden – sonst kann der Absturz eines einzelnen ndbd das ganze System zum Stillstand bringen. Meine beiden Data Nodes verfügen jeweils über vier Cores und 8GB RAM, und für den Anfang entschied ich, auf jedem zwei Instanzen des ndbd (und halt den mysqld) laufen zu lassen. Mit dieser Konfiguration schoss sich mein datanode1 dann gleich mal tot (Error data: DBTUP could not allocate memory for TableDescriptor) – sollen mehr Ressourcen zur Verfügung gestellt werden, muss man dem System mehr Ressourcen zur Verfügung stellen. Oder so ;) Jedenfalls erhöhte ich das RAM für meine Data Nodes auf 12GB (!) und passte die config.ini ein weiteres Mal an.
Nach vielen Spielereien entschied ich mich dazu, meine Test-Datenbanken alle zu trashen und bei Null zu beginnen. Dazu sind die folgenden Schritte nötig:
- Auf allen Data Nodes die
ndbd-Prozesse beenden. - Auf allen Data Nodes die
mysqld-Prozesse beenden. - Auf allen Management Nodes die
ndb_mgmd-Prozesse beenden. - Prüfen, dass auch wirklich alle Prozesse überall beendet sind!
-
Auf allen Data Nodes nacheinander
- den Inhalt von
/var/lib/mysql-clusterlöschen:rm -rf /var/lib/mysql-cluster/* - das Verzeichnis für die Datenbanken neu anlegen und die Rechte setzen:
mkdir /var/lib/mysql-cluster/data && chown mysql:mysql /var/lib/mysql-cluster/data - die grundlegenden Datenbanken installieren:
cd /usr/local/mysql && ./scripts/mysql_install_db - die Zugriffsrechte dieser Datenbanken setzen:
chown -R mysql:mysql /var/lib/mysql-cluster/data - den
mysqldstarten:/etc/init.d/mysql.server start - den
mysqldabsichern:cd /usr/local/mysql && ./bin/mysql_secure_installation - den
mysqldbeenden:/etc/init.d/mysql.server stop
- den Inhalt von
- auf den Management Nodes den Inhalt von
/var/lib/mysql-clusteraußer derconfig.inilöschen:rm -rf /var/lib/mysql-cluster/ndb*
Das System kann nun wieder durchgestartet werden:
- Im ersten Schritt lege ich den Management Nodes die neue config.ini (nach
/var/lib/mysql-cluster) - und starte sie dann durch; das
--initialmuss nicht mitgeschickt werden, wenn man ohnehin bei Null anfängt, es schadet aber auch nicht:ndb_mgmd --initial -f /var/lib/mysql-cluster/config.ini --configdir=/var/lib/mysql-cluster - Wenn diese fehlerfrei laufen (Logfiles beachten!), können auf den Data Nodes die
ndbdgestartet werden; der Aufrufndbd --initialmuss nun doppelt getätigt werden, denn auf jedem Knoten soll der Dienst ja auch doppelt laufen! - Wenn auch diese sich korrekt gemeldet haben, kann im letzten Schritt der mysqld auf beiden data nodes den Betrieb aufnehmen:
/etc/init.d/mysql.serverstart
ndb_mgm> show
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 4 node(s)
id=10 @10.0.2.10 (mysql-5.6.24 ndb-7.4.6, Nodegroup: 0)
id=11 @10.0.2.11 (mysql-5.6.24 ndb-7.4.6, Nodegroup: 0, *)
id=12 @10.0.2.10 (mysql-5.6.24 ndb-7.4.6, Nodegroup: 1)
id=13 @10.0.2.11 (mysql-5.6.24 ndb-7.4.6, Nodegroup: 1)
[ndb_mgmd(MGM)] 2 node(s)
id=1 @10.0.2.20 (mysql-5.6.24 ndb-7.4.6)
id=2 @10.0.2.21 (mysql-5.6.24 ndb-7.4.6)
[mysqld(API)] 2 node(s)
id=20 @10.0.2.10 (mysql-5.6.24 ndb-7.4.6)
id=21 @10.0.2.11 (mysql-5.6.24 ndb-7.4.6)
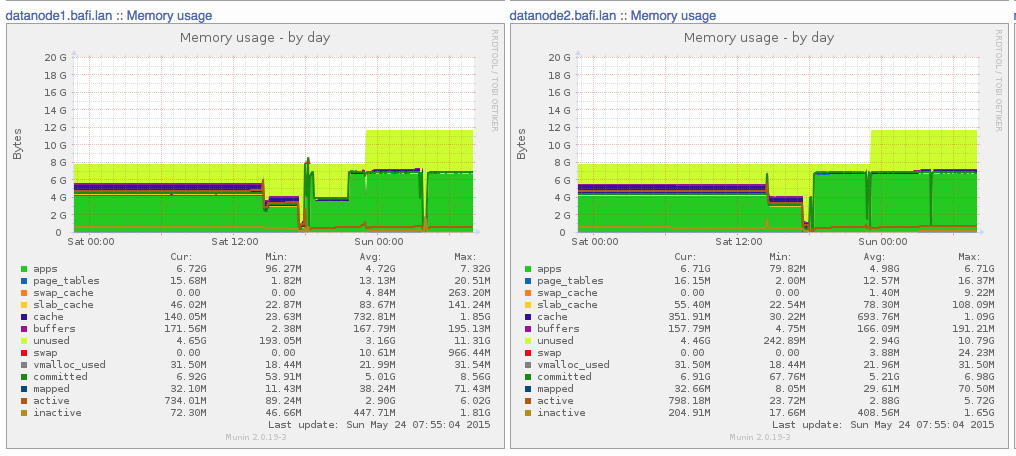
Funktioniert alles? Meine Data Nodes ziehen nun im Leerlauf knappe 7GB RAM. Die node groups replizieren sich über Kreuz. Fällt einer der Data Nodes aus, fehlt also beiden Node Groups sozusagen ein „Partner“, das System wird aber weiterlaufen. Sobald diese beiden ndbd wieder verfügbar sind, werden sie von einem der Management Nodes sozusagen auf Stand gebracht und nehmen, sobald sie synchronisiert sind, den Dienst wieder auf. Und im nächsten Schritt beschäftige ich mich dann damit, wie ich meine Dienste überwachen könnte…
Hintergrundbild: Bild genauer anschauen – © Marianne Spiller – Alle Rechte vorbehalten
{kind=link}